
Retour d’experience(’17) sur la gestion de la haute disponibilité avec Microsoft Azure
Je vais essayer de garder le rythme et de continuer à partager des retours d’experiences, apprentissages ou choix que nous effectuons sur inwink depuis 2 ans.
Après les micro-services, l’occasion se présente de parler de la gestion des services dans Azure, en terme de haute disponibilité et de scalling de ressources.
Microsoft experiences’17, qui s’est déroulé les 03 et 04 Octobre derniers, est le plus gros évènement IT en Europe en terme de fréquentation, et génère donc un trafic web considérable.
inwink est utilisé en mode SaaS pour gérer l’ensemble de cet évènement :
- La logistique et la gestion du contenu : agenda, session, speakers, partenaires, via notre backoffice
- Le flux du visiteur (accueil, badges, scans) au travers de notre applicatif inwink onsite
- L’expérience du visiteur par le site web et l’application, générés par notre module CMS en backoffice
- L’expérience des partenaires pour scanner les badges au travers de l’application de l’évènement
Etant sur une architecture nous permettant de distribuer notre produit en mode SaaS, il est bien sûr primordial, lors d’un évènement majeur comme celui-ci, que les performances et temps de réponse de notre plateforme ne soient pas dégradés pour l’ensemble de nos autres clients.
Dans notre métier, l’évènementiel B2B, nous sommes sur un pattern de charge très adapté aux architectures Cloud.
Concrètement :
- Avant l’évènement, nous avons des pics de trafic de 8h à 12h, puis de 14h à 18h. La taille de ces pics augmente de semaine en semaine jusqu’à l’évènement
- La veille de l’évènement, nous avons une forte hausse de trafic (vérifications des agendas, pré-impression de badge)
- Le jour de l’évènement, nous avons le plus gros pic de charge lié à deux facteurs : la fréquentation des utilisateurs sur le site et l’application de l’évènement. Ceci est complété par la génération de données logistiques tels que les scans de sécurité ou l’inscription sur site.
Voici par exemple le trafic de notre API sur les 20 derniers jours :
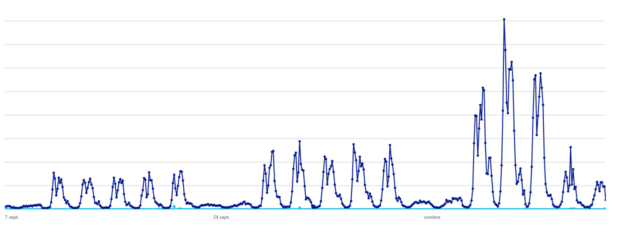
Combiné avec celui de notre API logistique utilisée majoritairement pendant les évènements :
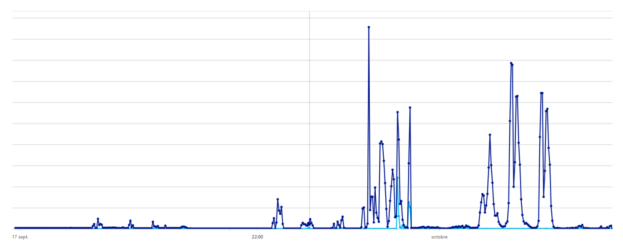
Dans la 1ère version de notre architecture, nous avions fait le choix de développer une seule API centralisant l’ensemble des traitements. Nous avions fait ce choix pour améliorer notre productivité : partage de code métier et données et simplification du déploiement en ne gérant qu’un seul gros service.
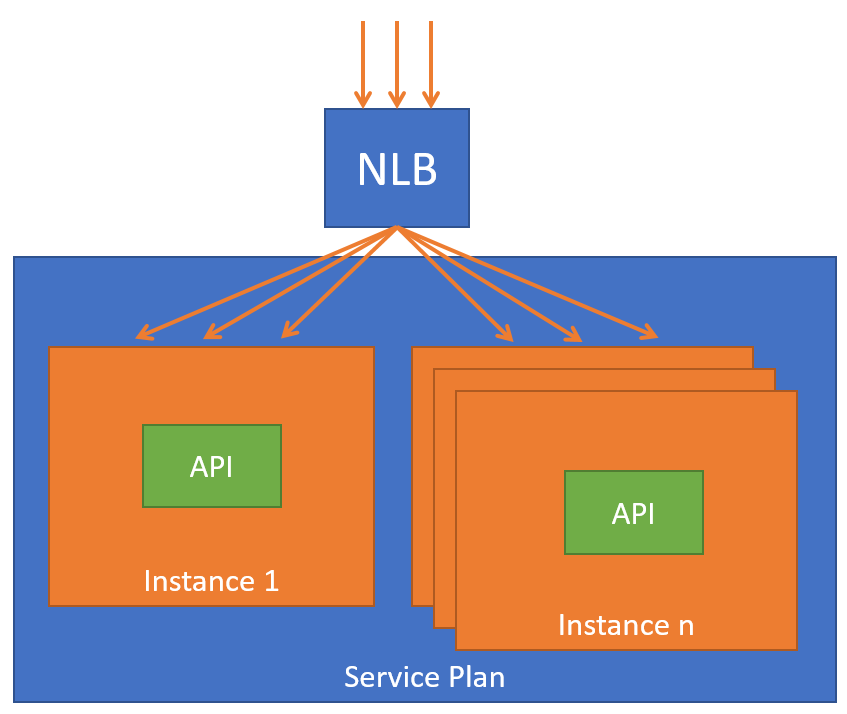
Ce choix nous a posé plusieurs problèmes :
- Une hausse d’appels d’un service peut dégrader les temps de réponses d’un autre. Par exemple, lorsque 4300 personnes sont scannées en logistique pour rentrer dans un amphi, cela ne doit pas empêcher les visiteurs déjà installés de consulter leurs agendas.
- Une difficulté pour optimiser les appels en termes de cache : des contrôleurs se retrouvaient utilisés par plusieurs services, mais avec des politiques de cache différentes. Par exemple, lorsqu’un speaker est modifié en backoffice, le cache doit être invalidé pour voir tout de suite sa fiche. Par contre, pour le front, le cache peut expirer seul pour être rafraichi 10 minutes plus tard
- Une difficulté pour monitorer quel service génère le plus de flux
- Et surtout, une difficulté pour scaler un seul service
En apprenant de nos erreurs, nous avons donc fait les choix suivants :
- Découpe de notre API en termes de projets, de code et de serveurs avec des services les plus autonomes possibles : API back, API front, API logistique, API d’authentification…
- Mise en place des outils de mesure du trafic côté serveur, avec Microsoft Application Insight
- Mise en place d’une stratégie de caching complète (client caching, output caching, Redis) – j’y reviendrai dans un prochain retour d’expérience
- Et surtout, mise en place d’une stratégie de scaling et de répartition des ressources pour absorber les pics de charge majeurs.
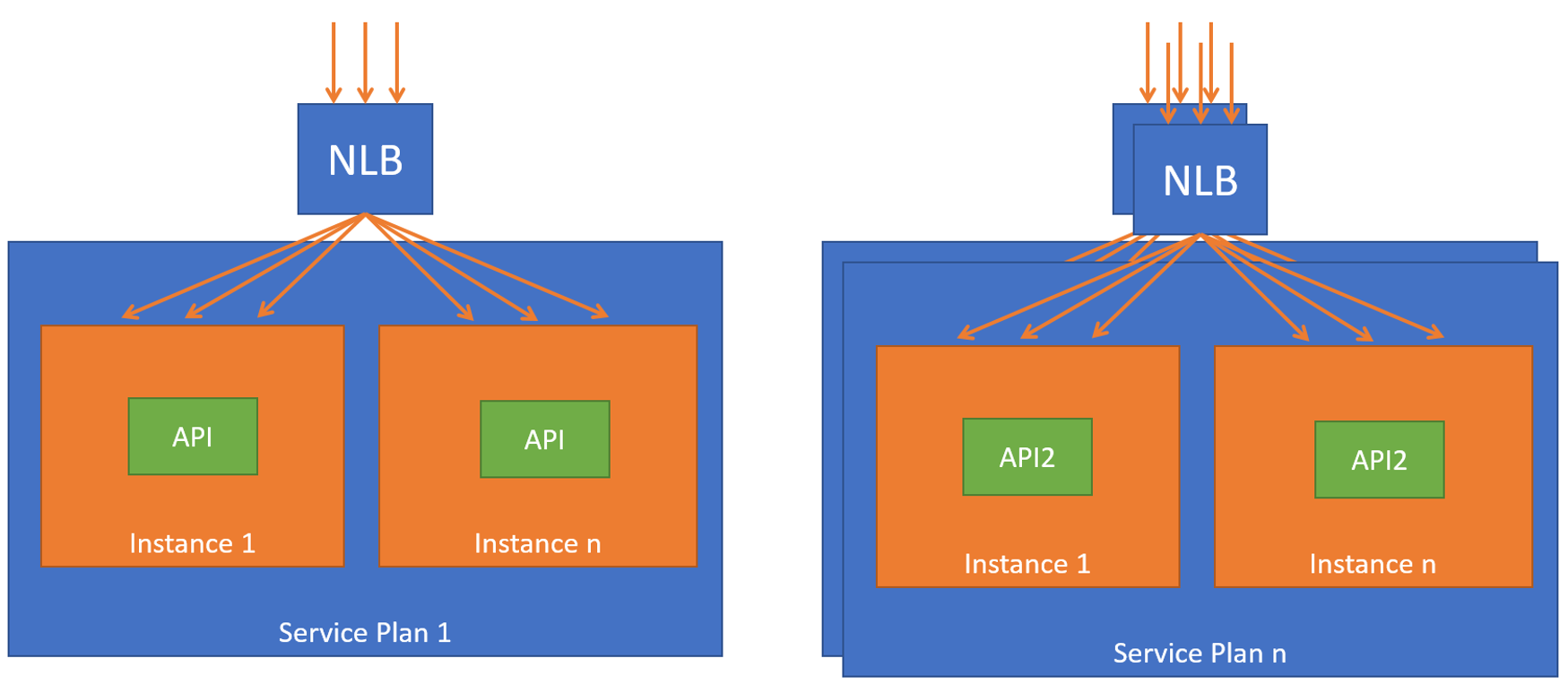
Au niveau de la gestion de ressources, sur un usage normal, nous fonctionnons de la sorte :
- Au quotidien, l’ensemble de nos services sont hébergés dans un même service plan Azure, contenant des machines load-balancées. Les services partagent donc les mêmes ressources.
- Ce service plan est configuré pour augmenter automatiquement le nombre de machines en fonction de l’utilisation de ses CPU : si le total de la consommation moyenne des CPUs est > à 50% pendant 5minutes, un serveur est ajouté. Si elle est < à 40% pendant 10 minutes, un serveur est enlevé (en gardant toujours au moins 2 serveurs pour garantir la disponibilité en cas de défaillance physique).
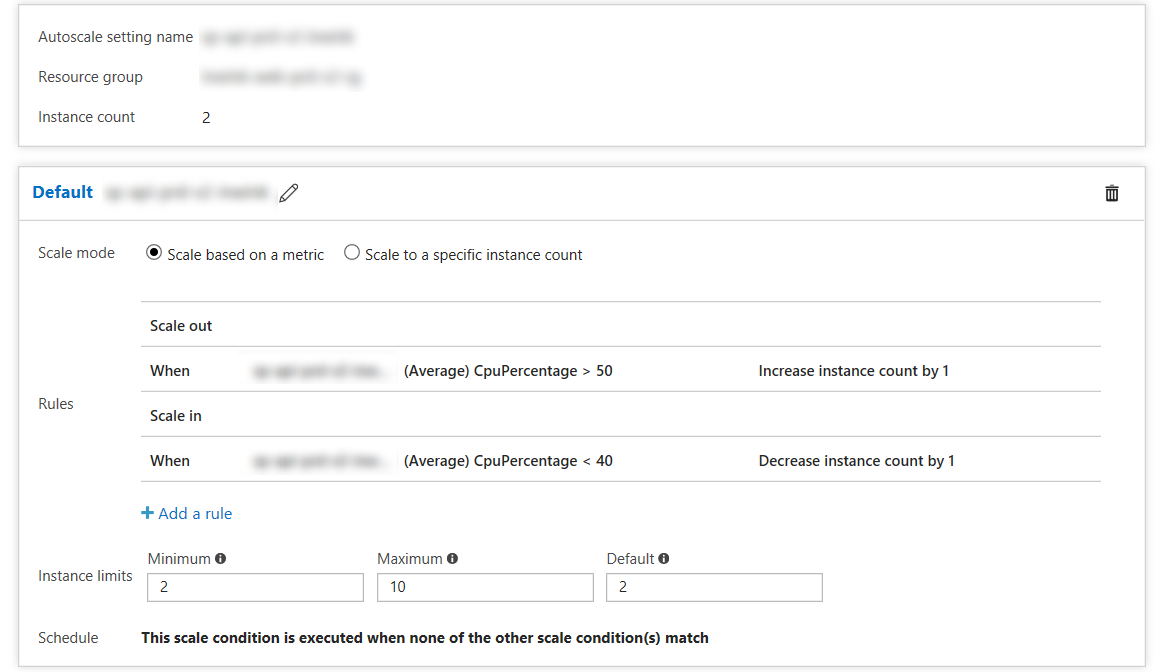
Avec ce mode, nous avons donc uniquement 2 machines utilisées la nuit, nombre qui augmente automatiquement la journée lors des pics de charge non prévisibles, tels que par exemple ceux subis suite à une campagne de mailing d’invitation.
Initialement, nous scalions en surveillant comme métrique la QUEUE de notre load balanceur (le nombre de requêtes en attente). Mais il s’avère finalement que cette métrique n’est pas adaptée : pour des temps de réponse optimale, il faut impérative que la QUEUE soit toujours vide, quand il y a des requêtes dedans en attente, les temps de réponse sont déjà dégradés et il est donc trop tard pour agir. C’est en observant nos serveurs sur des évènements majeurs que nous en avons déduit que, dans notre contexte, le CPU était la métrique à surveiller pour nous, car quand le CPU est saturé, il ne peut plus traiter de requêtes, et donc, il génère de la QUEUE, et dégrade les temps de réponse.
En cas d’évènement majeur et de pic de charge anticipé, nous effectuons les actions suivantes :
- Isolation des différents services sur des Service Plans (machines) différentes
- Montée à l’échelle automatique configurée sur chacun de ces services
Ces manipulations sont automatisées au travers de scripts Powershell, et nous permettent de gagner en scalabilé et d’être plus fins dans la gestion de notre charge. Par exemple, si l’évènement d’un client génère beaucoup d’appel de type scan, car il y a beaucoup de contrôles de sécurité, le nombre de serveurs augmentera sur ce service sans impacté le nombre de serveur et les performances des frontaux ou autres applicatifs.
Enfin, pour monitorer tout ça, nous avons créé un simple tableau de bord de monitoring de production dans le portail Azure, avec comme indicateurs clés :
- Le nombre de requêtes traitées / d’erreurs
- Les temps de réponses des différents services
- Le CPU / mémoire des instances
- La queue des services
- Et d’autres indicateurs sur lesquels je reviendrai 😊
Si vous avez des questions, ou souhaitez également partager vos experiences, n’hesitez surtout pas à laisser un commentaire sur cet article !
Bon scaling !


Commentaires