
Retour d’expérience : De l’importance des logs dans un produit SaaS
S’il y a bien une chose que je regrette et une erreur que je ne reproduirai plus, c’est de sous-estimer l’importance des logs dès les premières phases de la conception d’un produit.
Sur inwink, nous avons attendu 6 mois avant de nous pencher sérieusement sur cet aspect, se contentant au début « d’un peu de log applicatif, histoire de ».
Le résultat était le suivant :
- Impossible de connaitre en un coup d’œil l’état de la plateforme de production
- Impossible de valider qu’une livraison de montée de version s’est vraiment bien passée
- Grosse difficulté à isoler les problèmes de production afin de les reproduire en environnement de développement
- Impossible de dissocier une mauvaise utilisation de la plateforme d’un vrai bug technique, ce qui engendre un effort considérable à chaque demande de support
Nous avons réglé ce souci il y a 1 an en mettant en place une vraie politique de log, accompagnée d’outils plutôt efficaces.
Je parle de plusieurs outils, car aucun outil ne peut faire des miracles et être adapté pour tout, car il y a plusieurs besoins auxquels il faut pouvoir répondre.
Ainsi, aujourd’hui, en production, nous avons dissocié :
- Les logs applicatifs : tout ce qui se passe dans le code de l’application, autant sur les appels http que sur les services asynchrones, avec un niveau de verbosité complet (Information, debug, warning, error, critical).
- Les logs de trafic http : savoir ce qui s’est passé côté utilisateur, qui a fait quoi, pouvoir identifier facilement une requête lente.
- Les logs de trafic de base de données : sur SQL server, pouvoir savoir quels appels génèrent des soucis de performance
- Les logs de données : ce que font les utilisateurs, qui a modifié quoi et quand
Les logs applicatifs : Elasticsearch et Kibana
Comme évoqué précédemment, nous sommes dans une approche multi services / micro services, avec une 20aine de services composant notre environnement de production. Il était donc critique que chaque service dispose d’un service de log, et d’une interface graphique centrale pour consolider et analyser l’intégralité des logs. Pour ce point-là, nous sommes partis sur la combinaison classique Elasticsearch / Kibana, le premier pour stocker, le 2eme pour analyser, les deux hébergés en mode IaaS dans une VM Azure.
Le seul problème avec cette mise en place était que nous n’avions pas spécialement le réflexe au quotidien de nous connecter à Kibana. Pour simplifier la lecture et l’usage des logs, nous avons ainsi ajouté, directement dans notre backoffice, une interface de requêtage maison qui extrait directement les données utiles, en pré-appliquer nos filtres. De ce fait, nous avons directement l’information des services ayant des soucis depuis notre produit, en mode administrateur, et n’utilisons Kibana que pour les analyses très avancées.
Logs de Traffic HTTP : Application insights
Pour monitorer le traffic HTTPs sur nos différents services webs (front, back, api, authentification…), nous avons mis en place Application Insights.
Pourquoi application Insights ?
- Travaillant déjà sur Azure, cela se met en place en quelques minutes, sur nos environnements .NET et Node.JS
- Il apporte des informations de Traffic en temps réel (nombre de requêtes, nombre de requêtes en erreurs, …)
- Les données de Traffic sont corrélées avec les données de performance : impact d’une requête http sur le CPU, la mémoire consommée
- Nous pouvons descendre jusqu’à l’instrumentation et le profiling du code : isoler une requête ayant des problèmes de performance et pouvoir, directement depuis le portail Azure, voir les lignes de code éxécutées qui ont des soucis
Nous utilisons Applications Insights au quotidien au travers de trois modes :
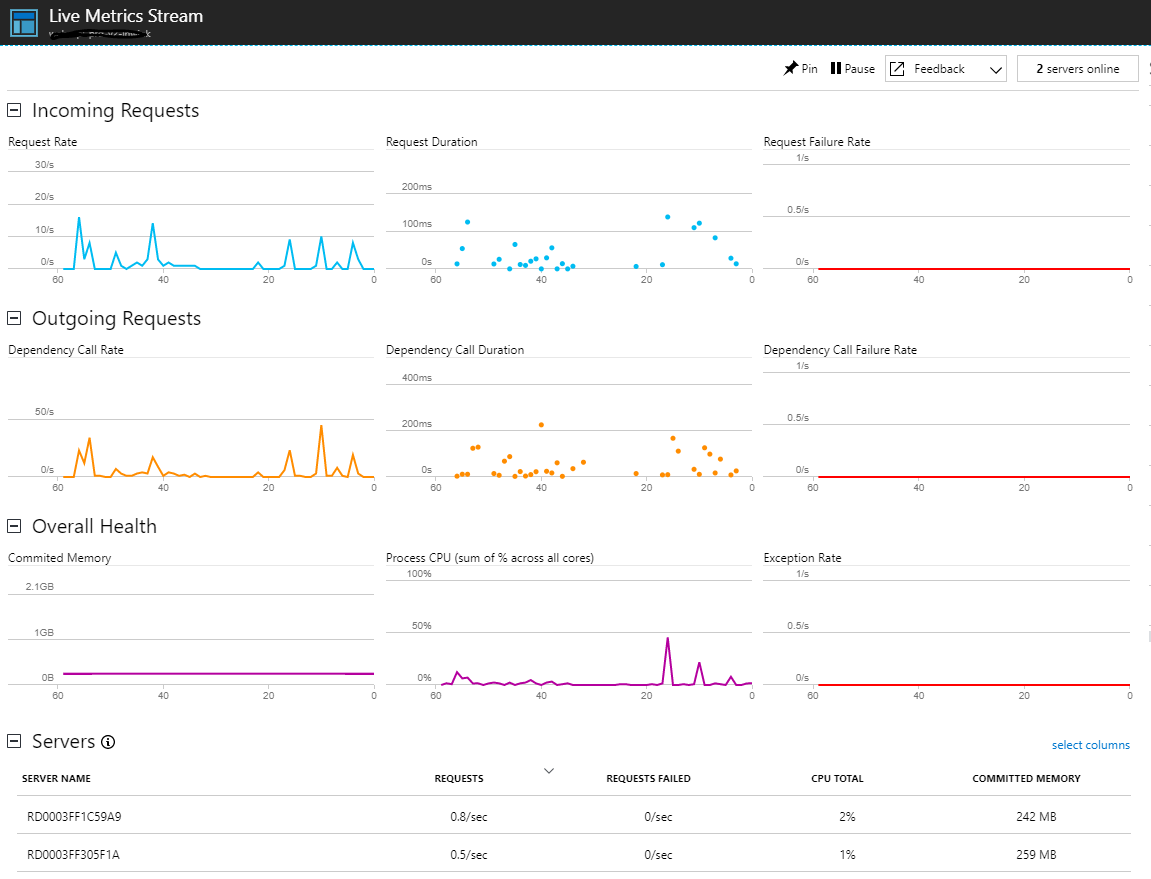
- Le mode « live metric Stream », pour monitorer en temps réel la plateforme
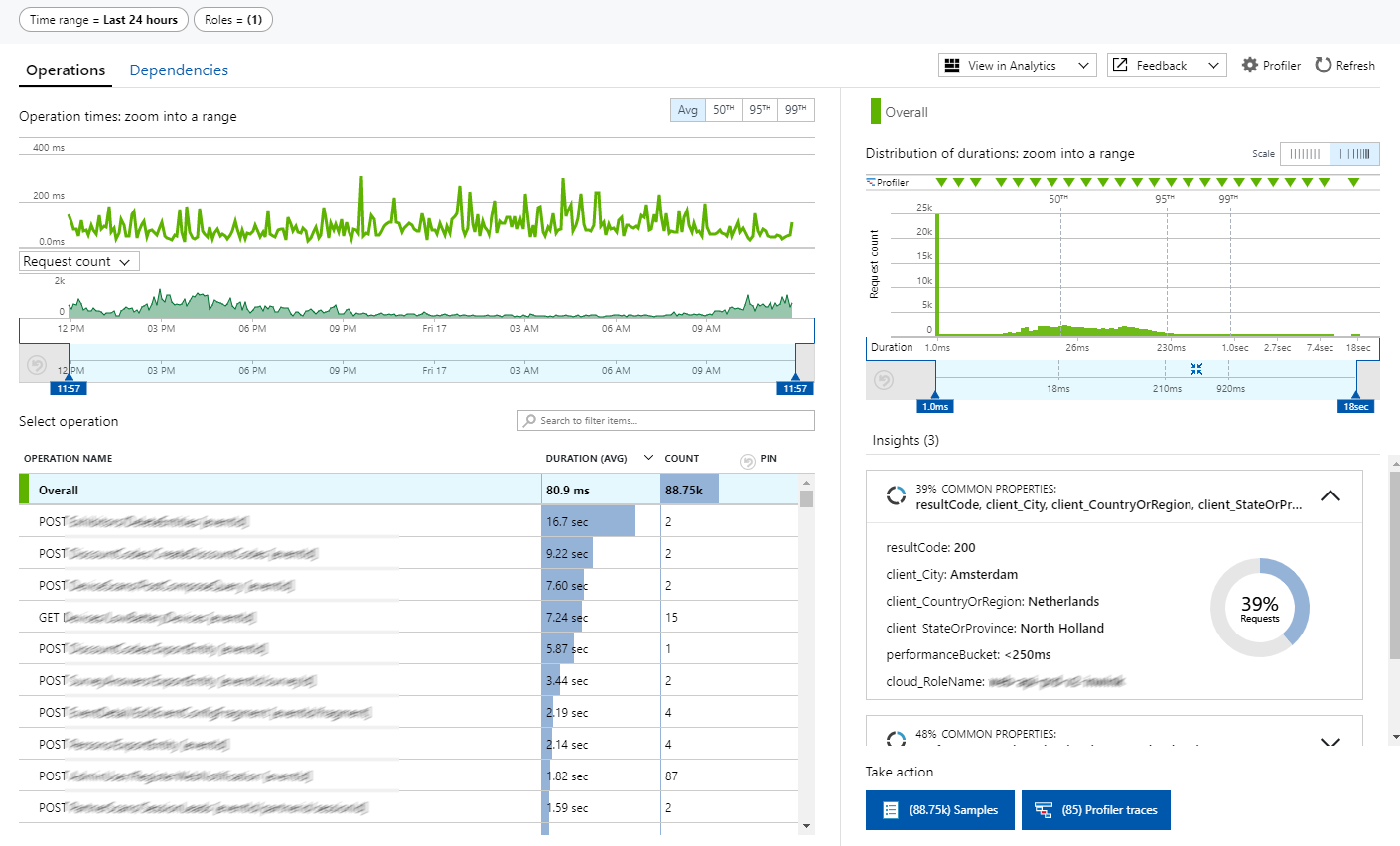
- Les tableaux de bord prêts à l'emploi, pour pouvoir détecter de manière macro les comportements récurrents à problèmes (requête générant le plus d'erreurs, la plus lente, la plus consomatrice de CPU...) :
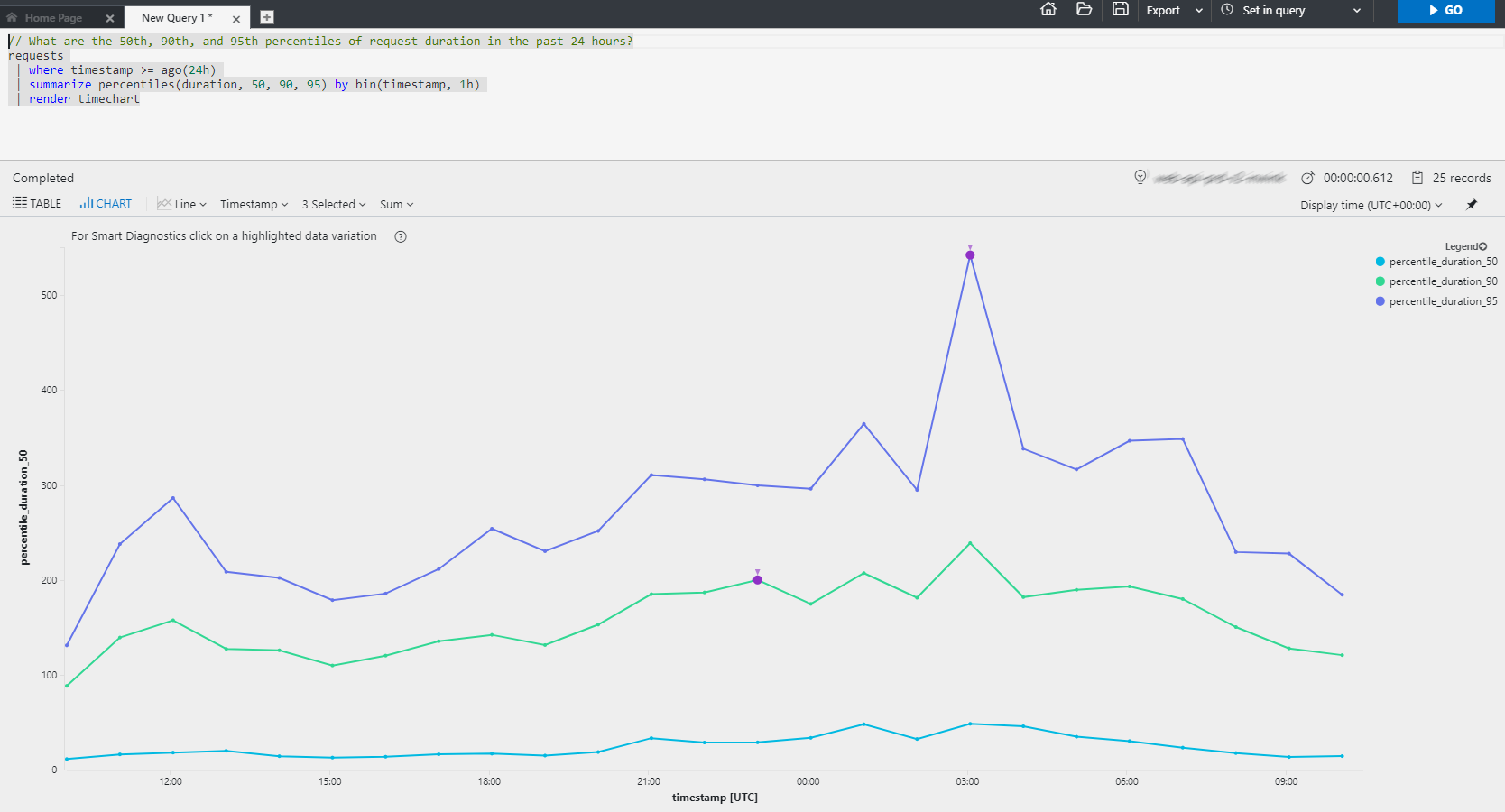
- Le mode « Analytics », ou recherche avancée, qui permet de requêter les logs en profondeur pour identifier des soucis (tel que le chemin de navigation d’un utilisateur qui a conduit à un problème de performance)
Analyste de performance de base de données : Query Performance Insights
Pour analyser et optimiser la couche relationnelle de système de stockage de données, nous utilisons également l’outil mis à disposition en standard par Azure pour SQL Database.
Ce tooling donne les informations suivantes :
- Liste des requêtes coûteuses en performance
- Liste des requêtes les plus appelées
- Propositions d’index, avec analyse d’impact après application pour valider l’intérêt
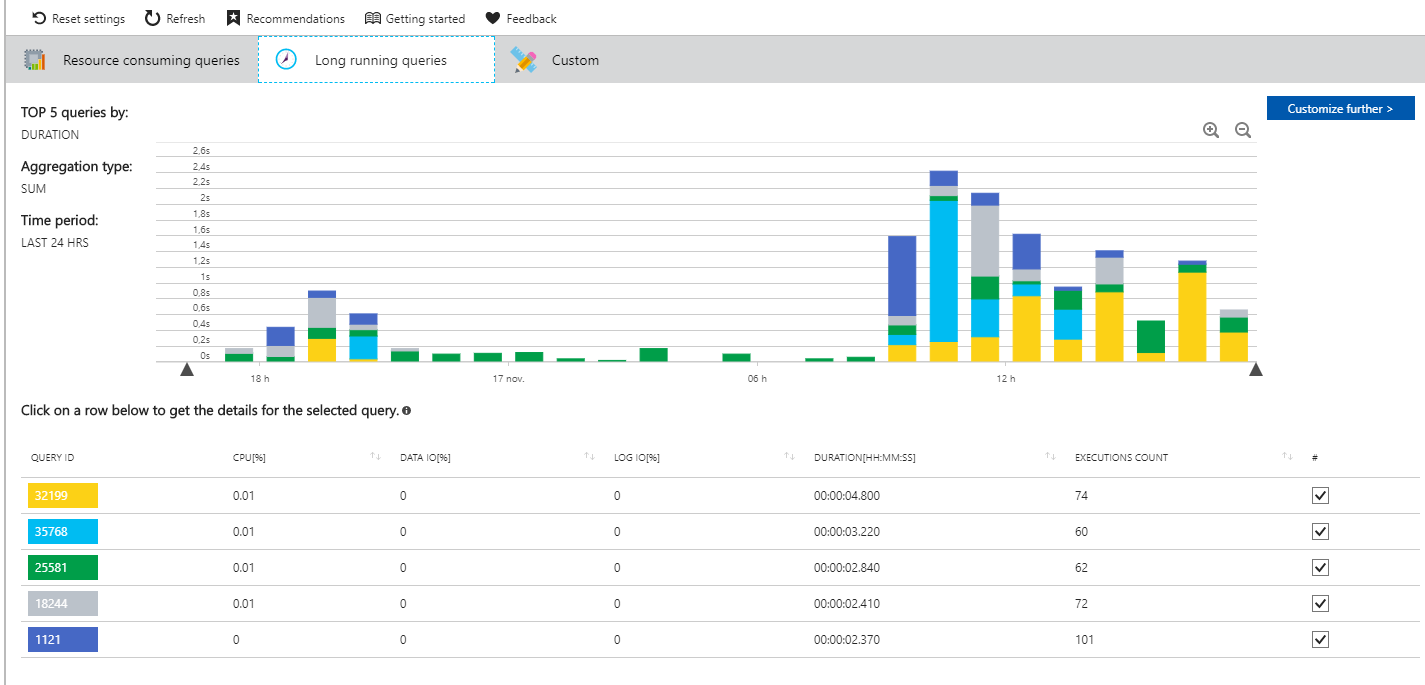
L’avantage de cet outil est qu’il est directement lié à Applications Insights, et qu’il est ainsi possible d’analyser un flux de requête dans son intégralité UI > API > BDD.
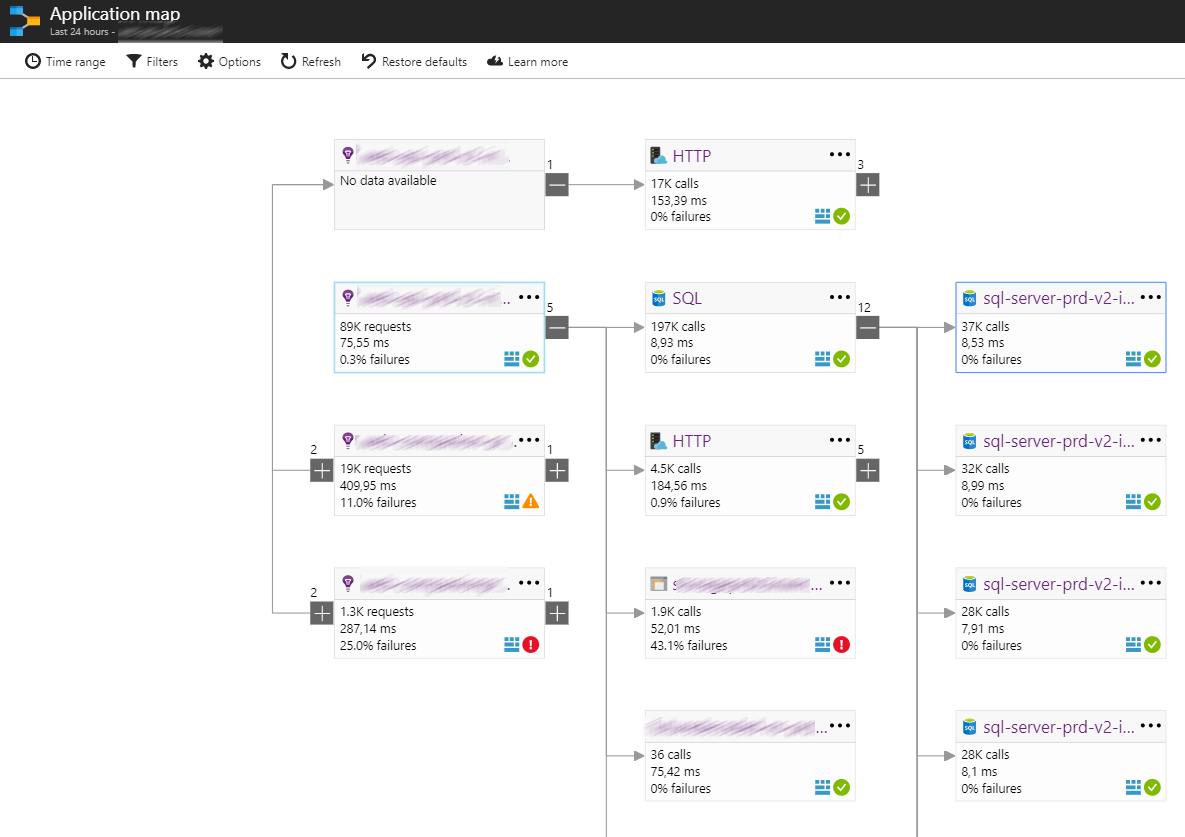
Logs et historisation de données :
Dernier point, pour éviter toute perte de données dans notre modèle relationnel, nous avons mis en place la fonctionnalité de « Temporal Table » introduite depuis SQL Server 2016 (https://docs.microsoft.com/fr-fr/sql/relational-databases/tables/temporal-table-usage-scenarios). Ceci permet, avec une simple modification du schéma de chaque table, de demander à SQL Server d’automatiquement sauvegarder dans une table d’historique les ajouts, modifications et suppression de données. Tout est géré au niveau du moteur SQL, sans aucune modification à apporter sur le code.
Pour activer ce mécanisme il suffit juste, dans la définition de chaque table à historiser, d’ajouter deux champs ValidFrom (date de début de validité de la donnée) et ValidTo (date de fin), et d’activer le versioning. Les données historisées seront stockées automatiquement dans une nouvelle table avec une syntaxe SQL dédiée afin de requêter des données dans le temps.
CREATE TABLE MyTable ( [xxx] int NOT NULL PRIMARY KEY CLUSTERED , [yyy] nvarchar(100) NOT NULL , [ValidFrom] datetime2 (2) GENERATED ALWAYS AS ROW START , [ValidTo] datetime2 (2) GENERATED ALWAYS AS ROW END , PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.MyTableHistory));
Avec ce principe, plus de possibilité de perdre de la donnée dans un modèle relationnel !
Ceci est juste une introduction des outils que nous avons mis en place, je tenterai ultérieurement, avec l’aide de mes camarades, de détailler plus en profondeur chaque brique.
Bons logs !


Commentaires